
不会写代码如何进行大数据分析——主题抽取篇
- 2020-04-10 10:43:00
- admin 原创
上一期文章中,锐研团队介绍了如何利用云文析对文本内容进行LDA主题模型分析,最终将新闻报道主题分为五类。LDA主题模型分析是一种无监督的统计学习,而今天我们将为大家介绍另一种主题分类的方法,在云文析平台中对应的功能是【主题抽取】。
和【主题分析】不同的是,【主题抽取】功能是用户先自定义一套主题逻辑,设定主题逻辑词典,即建立关键词词典,制定出每个主题下的关键词,再由云文析平台根据文本内容进行分类。这样分类的优点是在使用者已经充分掌握文本情况或主观层面有自己的需求,就可以根据既定的分类标准对批量文本进行分析。
还是以疫情期间收集到的1733条第一财经官网新闻数据为例,我们希望了解疫情对不同行业的影响,根据云文析已有的行业主题逻辑词典模板(主题逻辑词典模版2),我们开始着手分析:
一.选择主题逻辑词典
首先在锐研·云文析平台找到【分析配置】-主题逻辑,点击选择你需要的词典模版
行业主题逻辑词典模板是参考《财富中国》对中国行业的分类标准,它是根据发达国家的行业界定与行业演变规则,对中国的行业进行新分类。
具体使用时如有不同需求,可以点击左上角创建词典,对主题逻辑进行自定义,输入关键词规则即可。
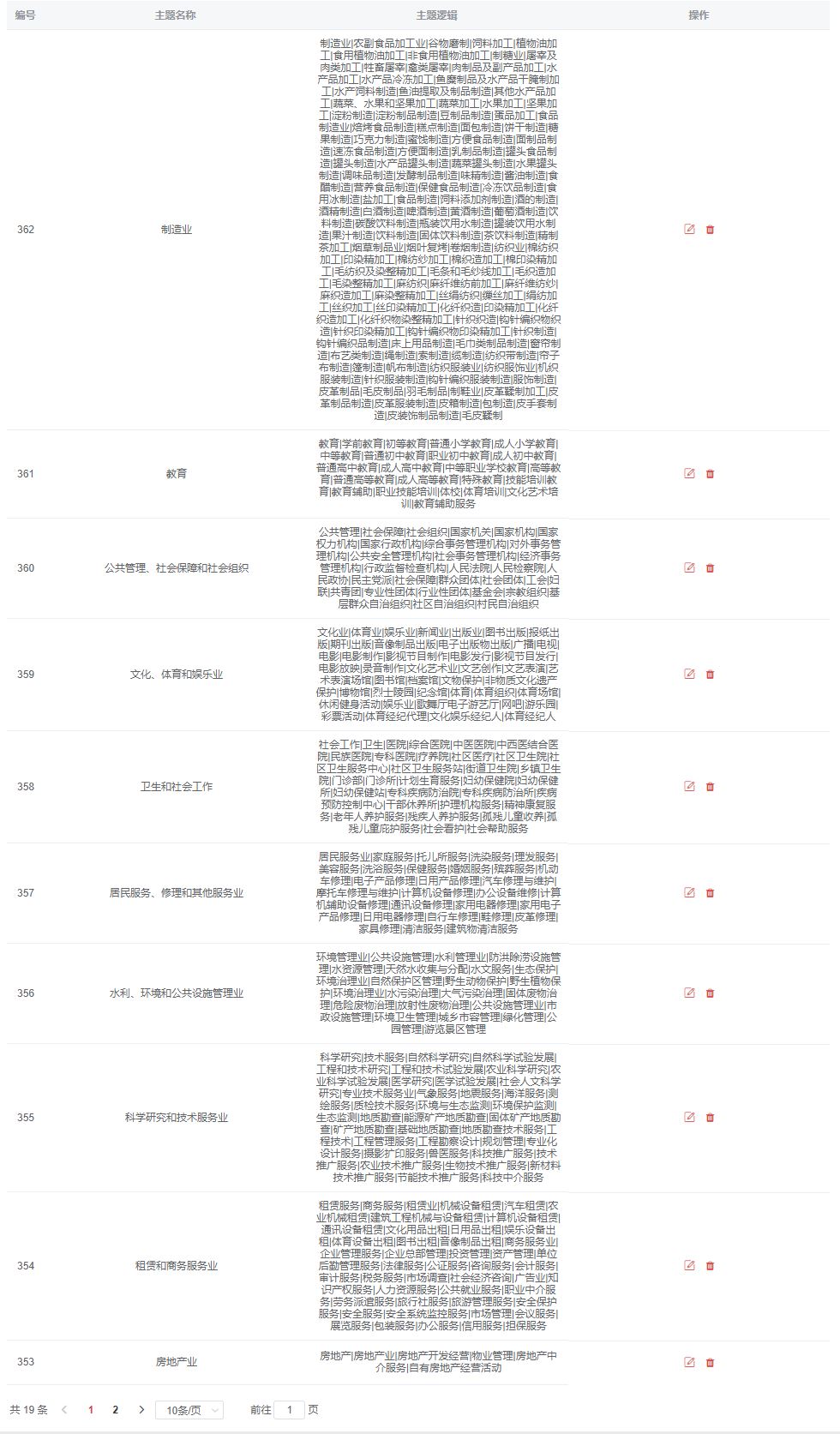
行业主题逻辑词典模板-部分
需要注意的是,自定义主题逻辑词典时要遵循一定的主题逻辑规则:
1.多个关键字同时匹配需要用 & 来连接,表示且的逻辑
2.匹配任意一个关键字用 | 来连接
3.支持括号()
比如,要提取“双创”这个主题,可以用 “双创 | (创新 & 创业)”作为主题规则,表示 只要文本中出现 “双创”或者同时出现 “创新”和"创业”,则该文本提及“双创”主题。
二.建立主题抽取
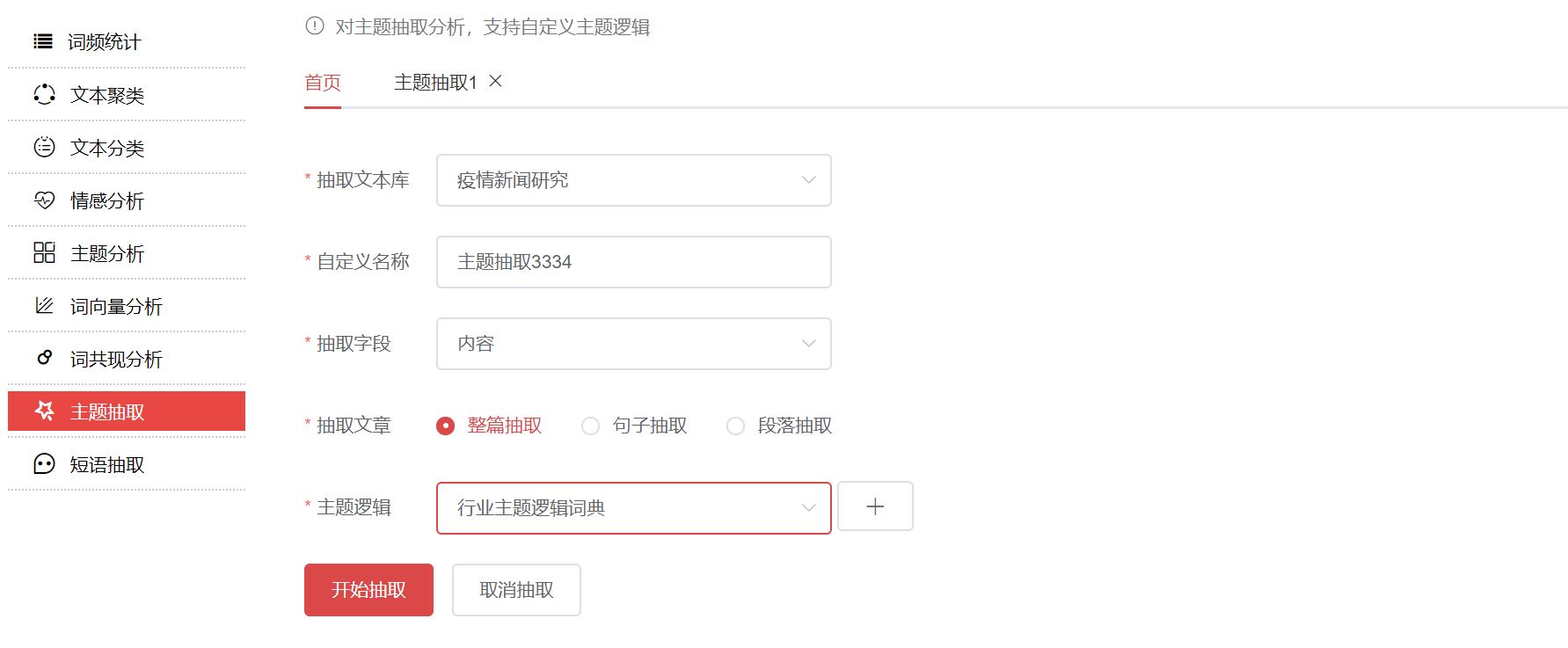
三.查看抽取结果
移动鼠标至条状图形可查看主题名称及具体数据。结果显示,这批报道中,卫生和社会工作相关主题的报道数量最多,达965篇;其次是金融业,文本数量达242篇;交通运输、仓储和邮政位列第三,文本数量达157篇;之后依次是教育、文化体育和娱乐业、制造业。
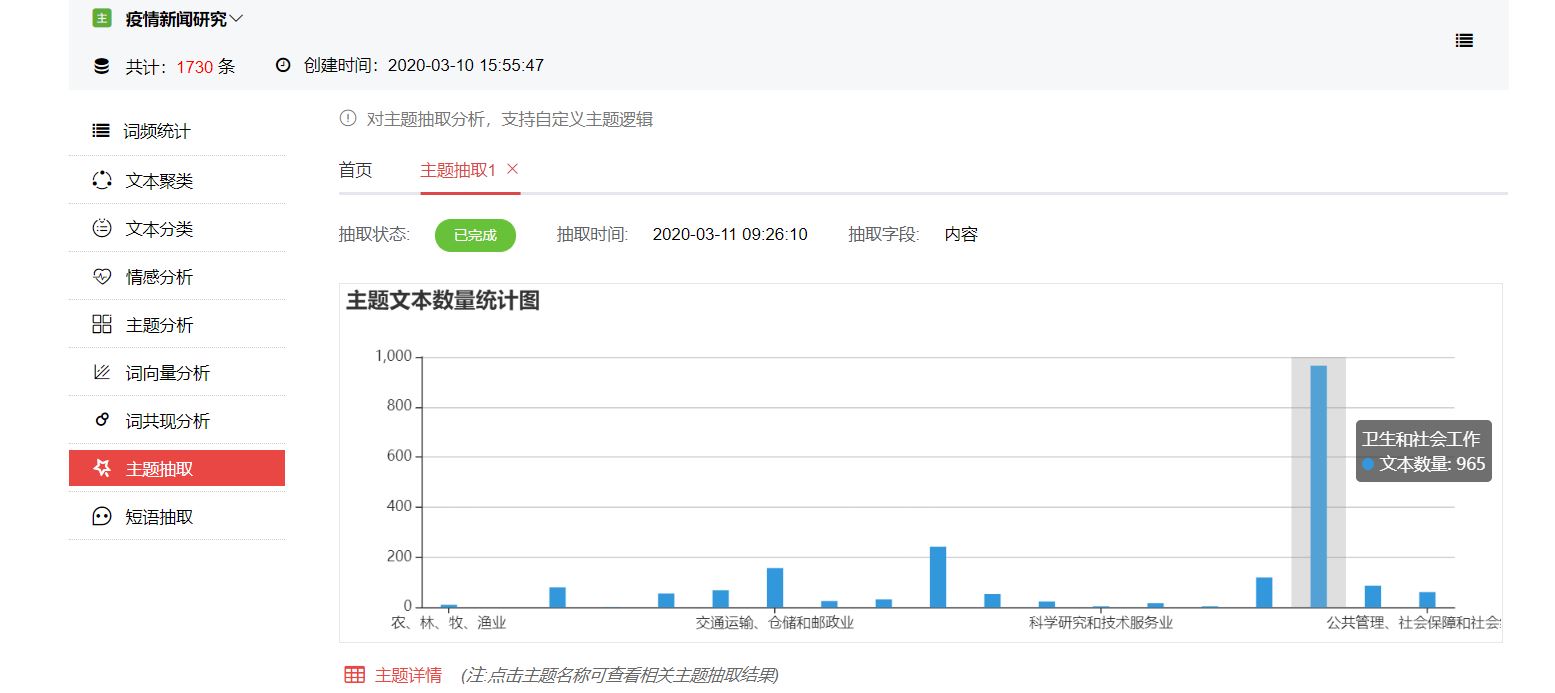
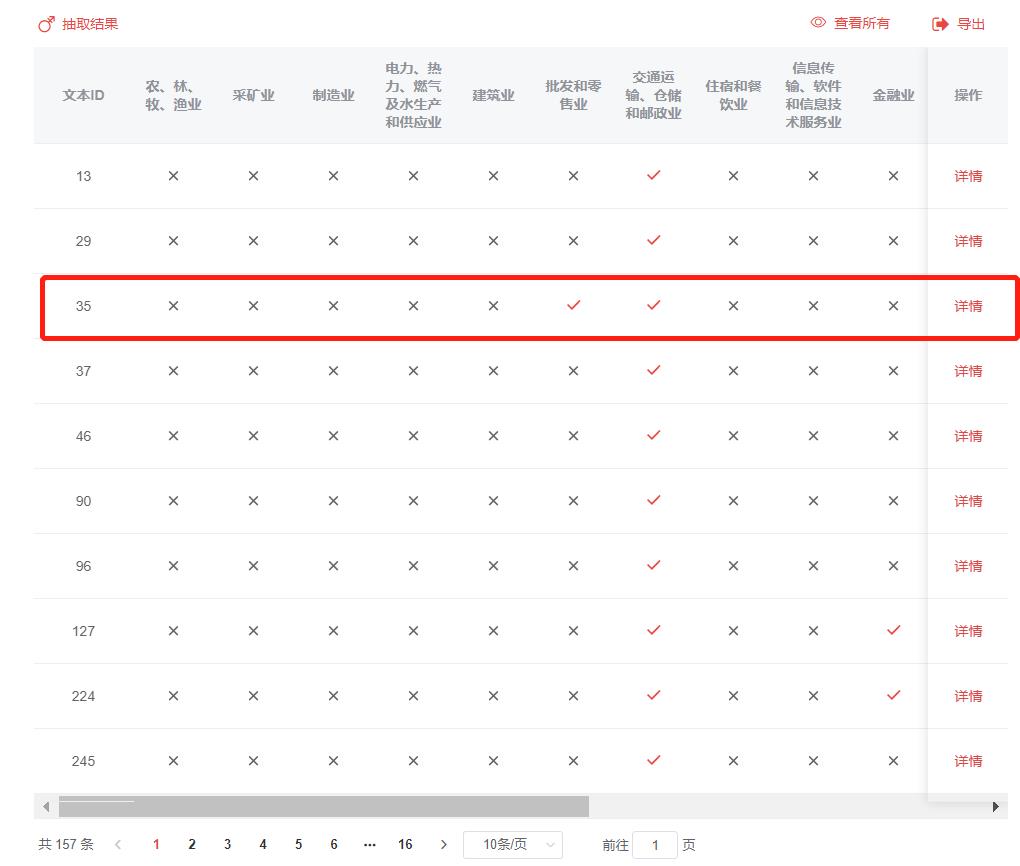
除了以柱状图形式展示主题文本数量,云文析还支持对抽取结果的详情展示,我们可以查看所有主题抽取类别下的文章,标记√的表示文章分属该类别,点击【详情】可查看文章具体情况,同时支持对分类数据的导出。
以文本ID为35的文章为例,该文章分属交通运输、仓储和邮政业主题,点击【详情】后我们可以看到文章的具体内容,用以判断分类标准是否合理以便后续分析。
锐研·云文析作为文本大数据分析与挖掘云平台,可应用自然语言处理、机器学习、人工智能等技术对大规模文本数据进行分析挖掘,并呈现可视化分析结果。今后,锐研团队会分享更多社会科学研究相关实用工具及案例,希望此文能为您提供一些帮助。
疫情期间,锐研云文析开放个人用户注册,有相关研究意向,欢迎扫描下方二维码联系我们的官方客服,为您开通更多权限。
